The Directed Acyclic Graph Manager (DAGMan) is a meta-scheduler for Condor jobs. DAGMan is responsible for submitting batch jobs in a predefined order and processing the results. A configuration file is defined prior to execution of DAGMan in which the jobs, their CondorConfigFile, and job dependencies are declared.
The importance of such a tool lies in the fact that the user is able to define the execution order of a number of Condor Jobs. Just as Condor schedules condor jobs, DAGMan schedules a system of jobs. In essence, it defines a problem. Solving a problem may require multiple condor jobs that need data from each other. This is best represented using a Directed Acyclic Graph (DAG), which represents the flow of control from one node to another (i.e., from one condor job to another) through arrows.
From the point of view of the user, the scheduler is initialized with the order of execution of jobs, and then started. DAGMan is responsible for all scheduling, recovery and reporting activities of the submitted system of jobs.
The following sections explain the use of DAGMan in full detail. However, if the user only wants the bare essentials, please read section 2.10.5 to get started more quickly.
For Unix users, a useful analogy might be to think of the DAGMan input file as a makefile, and DAGMan itself as the make executable. However, DAGMan differs from make. Instead of looking at file modification timestamps, DAGMan reads the Condor log file generated by each Condor job to find out which jobs are unsubmitted, submitted, or complete. DAGMan also makes a guarantee that a DAG is recoverable, even if the machine running DAGMan goes down during execution.
Job dependencies are defined prior to execution of the DAGMan program, using a DAG input file. An example input configuration file name is diamond.dag. The input file is read completely, and the DAG data structure is constructed in memory before the first job is submitted. With the exception of the CondorCommandFile (see below), the input file is case insensitive.
Throughout the input file, comments can be placed. Legal comments exist on a
single line which immediately starts with a `#' character, followed
by any characters up to the newline `
![]() n'.
n'.
It is interesting to note that the DAGMan input file does not contain any specifics about the individual jobs. Each condor job by itself is handled as if DAGMan was not present (this includes compiling and linking of the job). The executable and the input/output parameters for each job are contained in the CondorCommandFile. The DAG file merely describes the relationship between the different condor jobs using the semantics just described.
The Job Section of the input DAG file declares all the jobs that will appear in the DAG. Each job is described by a single line called a Job Entry. The following syntax is used:
JOB <JobName> <CondorCommandFile>
The JOB keyword (shown here in upper case only for clarity) declares this line will map a JobName to a Condor Command File. The JobName is used by DAGMan to uniquely identify jobs throughout the input file and to name them in output messages. The CondorCommandFile is the input file used by condor_submit to run the individual condor job. Because the Unix file system is case sensitive, the case of the CondorCommandFile is preserved.
The JobName can be any string that contains no white space. The JobName is not case sensitive, so ``JobA'' is equivalent to ``joba''. An example CondorCommandFile name is a.condor. Some important restrictions are placed on the contents of the CondorCommandFile, which will be discussed later.
The user can also have the option of declaring a job as being already completed in the DAG input file. This may be useful in situations where the user wishes to verify results, but does not need the entire job dependency graph to be executed. This is done by adding the word "DONE" to the end of the Job declaration line.
JOB <JobName> <CondorCommandFile> DONE
The dependency section of the DAG input file follows the Job Section and describes the dependencies between the jobs listed in the Job Section. The notion of a ``parent'' and ``child'' job is introduced here. A parent job produces output which is required by one or more child jobs. None of the children can run until the parent successfully terminates. A child job is one whose input is taken from one or more parent jobs. The child job cannot run until all of its parents have successfully terminated.
A single line in the input file can specify the dependencies from one or more parents to one or more children.
PARENT <ParentJobName>* CHILD <ChildJobName>*
The PARENT keyword is followed by one or more ParentJobNames. Those are followed by the CHILD keyword, which is followed by one or more ChildJobNames. Each child job depends on each and every parent job on this line. So the line ``PARENT p1 p2 CHILD c1 c2'' would produce four dependencies.
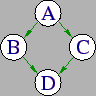
The following diamond.dag DAG input file shown below is illustrated in Figure 2.3.
# Filename: diamond.dag # Job A A.condor Job B B.condor Job C C.condor Job D D.condor PARENT A CHILD B C PARENT B C CHILD D
With diamond.dag, job A must execute first, because all other jobs directly or indirectly depend on it. After job A successfully completes, both job B and C are eligible to run. In fact, they will be submitted at the same time and hopefully Condor will find two remote hosts that can run them in parallel. Since job D depends on both B and C, it must wait for both to complete successfully before it can be submitted.
Each individual job in a DAG is free to be a unique executable, with a unique CondorCommandFile. The DAG can contain a mixture of standard and vanilla jobs, or even other meta-scheduler jobs, like DAGMan. On the other hand, the jobs in the DAG could all use the same executable, or even the same CondorCommandFile. Anything between both extremes is possible. However, two limits are imposed.
First, each CondorCommandFile must submit a cluster of size one. There cannot be multiple queue lines. The reasoning is long winded, so a brief summary will be attempted. If multi-job clusters were allowed, DAGMan would have to parse the CondorCommandFile to find out how many jobs belong to that cluster. Otherwise, DAGMan would not know for sure if a cluster had terminated based on seeing the event from one job of that cluster. This restriction may be lifted in future DAGMan version, depending on the design and implementation issues.
Second, all CondorCommandFiles of a DAG must specify the same log. In order for DAGMan to follow the order of events correctly, all events from all jobs in the DAG must be sent to the same log file. This restriction will be loosened in later versions (see section 2.10.6).
For this example, we will write a single CondorCommandFile to be used by all three jobs in the DAG. Thus, each job will run the same executable. Notice, that to use the same CondorCommandFile and still get unique filenames for our output, we use the $(cluster) macro. Since each job is submitted seperately, into its own cluster, this will provide unique names for our output files. Otherwise, the jobs would be clobbering each other's output.
# Filename: diamond_job.condor # executable = /path/diamond.exe output = diamond.out.$(cluster) error = diamond.err.$(cluster) log = diamond_condor.log universe = vanilla notification = NEVER queue
Note that notification is set to NEVER. This is recommended if you prefer not to have Condor send you e-mail for every job in a large DAG.
The DAG file names the jobs, associates jobs with their CondorCommandFile, and declares job dependencies. For our DIAMOND example, all four jobs will use the same diamond_job.condor file written earlier.
However, a more typical DAG file would have some different CondorCommandFile entries, since, presumably, some of the jobs in your DAG differ beyond where their output goes. If not, you probably don't even need DAGMan, you just need to submit a cluster for all your jobs.
# Filename: diamond.dag # DIAMOND DAG File for DAGMan # Job A diamond_job.condor Job B diamond_job.condor Job C diamond_job.condor Job D diamond_job.condor PARENT A CHILD B C PARENT B C CHILD D
This DAG file will be the input file for the condor_dagman program.
In order to guarantee recoverability, the DAGMan program itself is run as a Condor job. However, DAGMan is not submitted as a standard universe or vanilla universe job. Instead, it is run as a meta-scheduler. Standard and vanilla universe jobs are usually submitted to the local schedd, which schedules them for execution on some remote machine in the pool that is idle. A meta-scheduler is also submitted to the local schedd, but runs on the local schedd. The meta-scheduler then submits jobs, according to its design, to the same local schedd, just as if the user submitted them manually. In fact, the local schedd does not know the difference between DAGMan submitting a job, and the user who originally submitted DAGMan, and could have submitted the DAG jobs manually.
A DAG is submitted using the condor_submit_dag script. For example, to submit the diamond.dag DAG to Condor, simply type ``condor_submit_dag diamond.dag''. This script will generate the diamond.dag.condor.sub CondorCommandFile for the DAG, and submit it to Condor. If the user prefers to edit the diamond.dag.condor file before it is submitted to Condor (for example, to change the pre-chosen filenames), she can issue ``condor_submit_dag -no_submit diamond.dag'', which specifies that diamond.dag.condor is generated, but not submitted to Condor. To run the DAG, issue the command condor_submit diamond.dag.condor.sub.
Normally, condor_submit_dag will try to check your DAG input file for correctness. In particular, it tries to verify that all the jobs in your DAG specify the same log file (which is needed for DAGMan to properly function, as described above). If it finds a problem (a job that's using a different log file), it will print out an error message and abort. If you use the ``-verbose'' option, it will also print out a list of all jobs in your DAG and the corresponding log file each uses. However, in some situations, you may not want this check. For example, if you have a very large DAG (with thousands of jobs), opening up each submit file to verify its correctness might take quite a while. So, if you want to avoid this check, make sure you're using the same log file for all jobs in your DAG, and then just pass this log file's name to condor_submit_dag with the ``-log filename'' option. This tells condor_submit_dag not to bother trying to verify what log file to use, and it just uses what you tell it.
After submitting a DAG, the user may change her mind and wish to remove the entire DAG, plus any jobs submitted by that DAG which happen to currently be running. DAG removal is easily accomplished by issuing a condor_rm on the DAGMan job itself. The schedd sends a special signal to the meta-scheduler, telling it to remove any of its condor jobs (using condor_rm) that are currently running.
However, if the machine is scheduled to go down, and the schedd receives a shutdown command from the master, the schedd will send a running DAGMan job a similar shutdown, which instructs DAGMan to clean up memory and exit. However, in this case, DAGMan does not remove its submitted jobs, but rather expects them to persistently exist in the Condor queue after restart.
The important thing to remember is that DAGMan will not explicitly run condor_rm on its jobs except as a result of the user running condor_rm on the DAGMan job.
The Condor system offers the benefit of recoverability, in that if any host crashes, Condor jobs that were running can be recovered, either by continuing from the last checkpoint, or rerunning from scratch. In any event, Condor guarantees that once a job is successfully submitted, the Condor system will not loose it.
DAGMan makes the same guarantee about the DAG as a whole. If the machine running DAGMan goes down or crashes, upon restart DAGMan will be restarted, and the state of the DAG jobs will be recovered from the log file (diamond.dag.condor.log from our example before). DAGMan knows to recover a DAG (as apposed to starting a new one) because it will detect the existance of a lock file that was not removed from the last run. If DAGMan successfully finishes a DAG, the lock file is removed, so that the next run will not go into recover mode. The lock file is specified via command-line argument to DAGMan in the CondorCommandFile. Refer to section 2.10.2.
This section is written for those users looking for the boiled down, absolutely essential steps to successfully submit a DAG.
This section addresses the features and limitations that exist in the current version of DAGMan, and how they may change in future versions.
This first public release of DAGMan was written and tested in the Condor 6.1.0 environment. It is shipped separate from the main Condor system as a contribution program. As such, it is not as rigorously tested as the core components of Condor. A reasonable effort has been made to test large DAGS (on the order of 5000 jobs) on Solaris x86 and Sparc. However, the DAGMan is not arrogant enough to claim itself bug free. Users are encouraged to send e-mail to condor-admin@cs.wisc.edu.
The following feature summary compares the current version with possible versions of DAGMan still to come.